
think deeply
[EDA] 국내 E-Book 사용자 경험 분석(feat. 밀리의 서재, 리디북스, 윌라 오디오북) 본문
EDA(Exploratory Data Analysis, 탐색적 데이터 분석)
분석을 하기 위한 데이터를 살펴보는 과정을 의미하는 단어
도출하고자 하는 결과값을 좀 더 수월하게 낼 수 있도록 해당 데이터를 살펴보는 것입니다.
EDA가 필요한 이유
분석 코드를 어렵게 모두 작성해도 원하는 형태의 결과가 나오지 않을 수 있는데, 그럴 경우 그 시간이 모두 헛고생으로 돌아간다.
근원적으로 분석해야하는 데이터를 잘못 이해했기 때문이라고 볼 수 있다.
오늘은 현재 내가 분석하고자 하는 대상인
'국내 e-book에 대한 사용자 경험 분석' EDA 과정을 간략히 정리해두고자 작성한다.
1. 관련 raw data를 모으기 위해, 국내 구글 플레이 스토어 크롤링 진행
분석 대상에 대한 사용자 경험을 다루기 위해 적합한 데이터 중 구글 플레이 스토어에 담긴 앱 사용 리뷰를 활용하고자 크롤링을 진행했다.
대상은
국내 전통 도서커머스인 YES24, 교보문고, 알라딘
국내 신흥 전자책 서비스 제공 중인 밀리의 서재, 윌라 오디오북, 리디북스, 스토리텔
총 7개의 기업으로 잡았다.
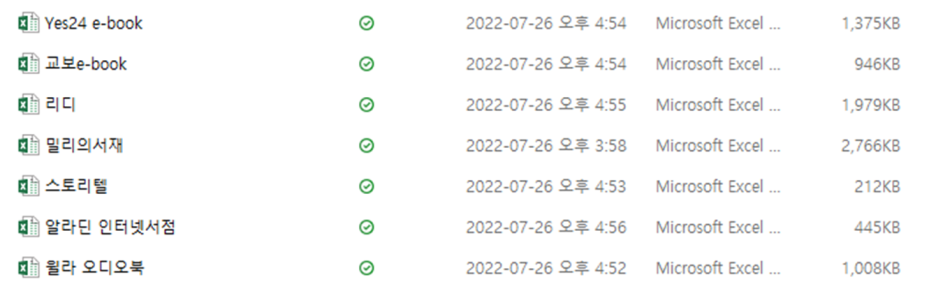
– 교보문고(4600개), Yes24(8700개), 알라딘(2900개)
– 밀리의 서재(13000개), 윌라 오디오북(4300개), 리디북스(11000개), 스토리텔(900개)
이 중 스토리텔은 총 리뷰 36만개 중 한글로 작성된 리뷰의 수는 900개 가량 뿐이었다.
따라서 국내 사용자 경험 분석이 대상인 이번 분석에서는 제외시켰다.
2. 결측치 처리 및 데이터 필터링
<작업>
- 데이터 프레임의 'content' 열의 값들을 str 형식으로 바꾸어줌
- 정규표현식을 통해 특수문자를 제거해줌
- 한글과 숫자가 아니면 빈 문자열로 바꾸어줌
-빈 문자열 NAN 값으로 바꾸어줌
- NAN이 있는 행은 삭제
- 데이터 프레임에 null값이 있는지 확인 후 인덱스 다시
3. 결과 및 시각화
코드는 사용하던 코드를 활용해 사전 분석을 진행하였고,
리뷰 하나를 하나의 문서로 보고
LDA분석을 진행하였다.
<결과 1>
'밀리의 서재, 윌라 오디오북, 리디'
세 기업을 기준으로 분석 진행
전처리 전: 총 28513개 리뷰
전처리 후: 총 14640개 리뷰

<결과 2>
'스토리텔을 제외한 6개 기업 모두'
전처리 전: 총 44721개 리뷰
전처리 후: 총 19725개 리뷰
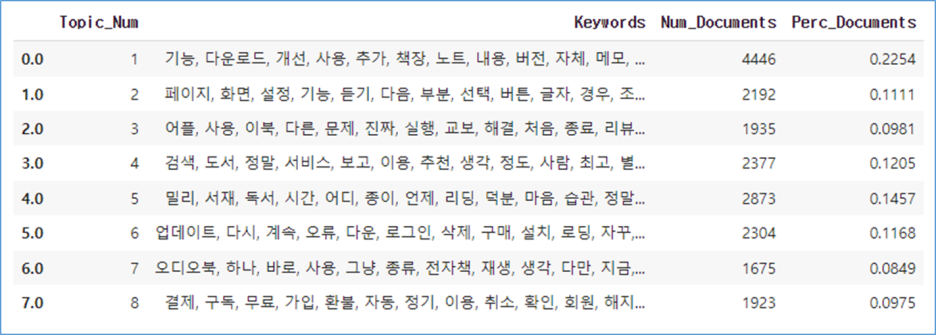
여기서 밀리, 정말, 진짜를 불용어처리하여 분석 한 번 더 진행
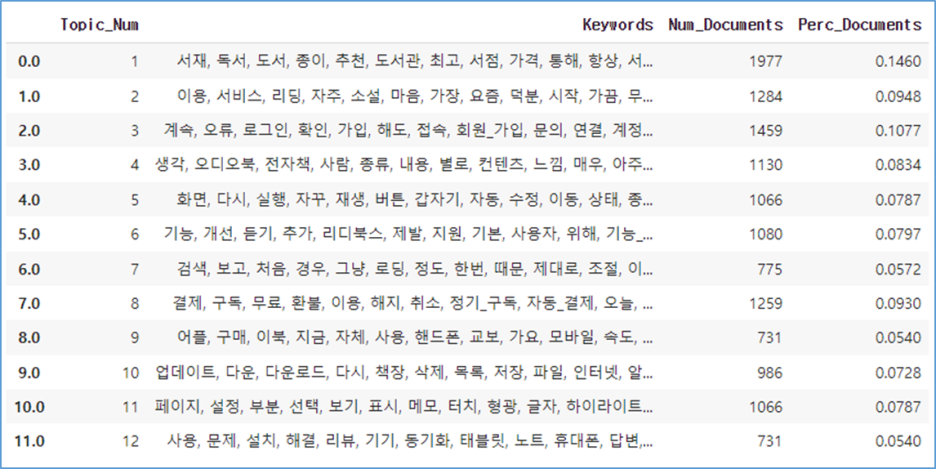
여기에 항상, 다시, 경우, 그냥, 매우, 별로, 처음, 계속까지 불용어 추가하여 한 번 더 진행

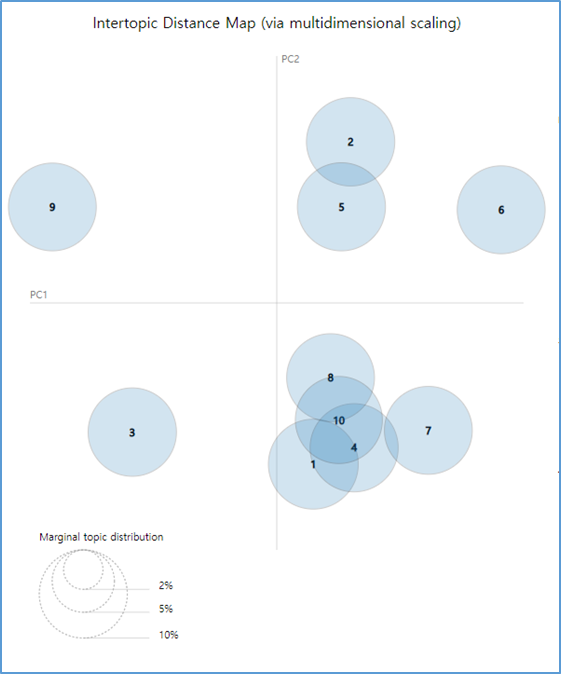
< EDA 결과 >
토픽들이 상위레벨로 나뉘어진다.
내가 분석해서 도출하고자 하는 인사이트는 로우레벨에 위치하기에
더욱 상세하게 토픽이 나뉘어야한다.
따라서 리뷰 하나를 문장별로 나누어,
한 문장을 문서로 취급하여 더욱 상세하게 내용이 나뉘도록 한다.
또한, 문서의 수도 더욱 늘어나기에 LDA로 나뉘어진 토픽 내에서
한번더 LDA를 진행할 수 있을 것이다.
'rainbow > etc.' 카테고리의 다른 글
| [Python] where()함수 - 조건에 맞는 값 위치 or 값 변경 (데이터프레임 특정 칼럼) (0) | 2023.02.20 |
|---|---|
| [python] 문자열 거꾸로 출력하는 방법 (feat. reverse, reversed) (0) | 2023.01.07 |
| [will-tech] ChatGPT :: 세상에 아직 없으면 만들어줄게(feat. 사용법) (0) | 2022.12.29 |
| [Mac] Mac 화면 분할 단축키 사용 방법 (0) | 2022.10.13 |
| [크롤링] 내가 원하는 구글 플레이 스토어 앱리뷰 크롤링 (0) | 2022.07.26 |



