
think deeply
[논문] Wide & Deep Learning for Recommender Systems (feat. 추천시스템) 본문
0. intro
1. abstract
2. introduction
3. recommender system overview
4. wide & deep learning
5. system implementation
6. conclution
0. intro
wide and deep은 2016년 구글이 발표한 추천랭킹 알고리즘이다. 딥러닝 기반 추천시스템의 입문용 논문으로 많이 읽힌다.
구글 플레이 스토어 앱의 user의 검색 기록(query)를 바탕으로 생성된 추천할 앱(candidate)을 rank하는데 적용된다.
1. abstract
sparse한 inputs인 큰 scale의 회귀, 분류 문제에 nonlinear feature를 변환한 Generalized linear model이 보편적으로 활용된다.
(Generalized linear model이라함은 로지스틱 회귀 모델을 예로 들 수 있을 것 같다.)
feature 간 interations (ex. cross-product feature transformations)를 통한 memorization은 효과적이고 해석 가능하지만, generalization하기에는 피쳐 엔지니어링 노력이 필요하다.
deep neural network는 저차원 dense한 임베딩을 통해, 더 적은 피쳐 엔지니어링 노력으로 feature combination을 generalize할 수 있다. 하지만, deep neural network의 임베딩은 user-item interaction이 적거나 엄청 많은 경우, 지나친 일반화로 덜 연관성 있는 아이템을 추천하게 되는 문제를 발생시킨다.(데이터 특징을 자세히 기억하지 못하는 문제 발생)
본 논문은 memorization에 특화된 linear wide 모델과, generalization에 특화된 non-linear deep모델을 결합한 wide and deep 모델을 제안한다.
2. introduction
추천시스템은 memorization과 generalization 모두를 달성해야하는 목표가 있다.
루즈하게 정의·비교해보면, memorization은 item이나 feature의 빈번한 동시출현을 학습하고, 상관분석을 활용한다. 이는 추천시스템에서 직접적 관계있는 상품을 추천해주게 되는 경향이 있다.
generalization은 transitivity of correlation에 기반하고, 과거에 거의 발생하지 않았거나 없던 새로운 feature 조합을 찾는다. 그리고 이는 추천시스템에서 추천 상품의 다양성을 높여주는 경향이 있다.
* transitivity : a >b && b>c 이면 a>c가 성립한다. 이런 관계를 transitivity라고 한다.
<기존 모델의 한계>
Generalized Linear Model
- Logistic Regression같은 방법을 활용
- 원핫 인코딩으로 binarized sparse features를 학습함
- cross product transformation을 사용하여 Memorization에 특화되게 됨
- cross product transformation 한계점: 데이터에 나타나지 않는 query-item feature pairs을 특징으로 generalize하기 어려움
- 즉, unseen data (새로운 또는 관측되지 않은 데이터)에는 취약하며 overfitting이 발생 가능
Embedding based Model
- Factorization Machine, Deep Neural Network 방법을 활용
- Generalization (unseen data 대응)에 특화됨
- 특정 선호도를 가진 사용자나 narrow appeal을 가진 항목과 같이 matrix 내 희소한 경우, 저차원 특징을 효과적으로 학습하는 것이 매우 어려움
- 이러한 경우, 대부분의 쿼리 항목 쌍 사이에 interaction이 없어야하지만, dense embedding은 non-zero prediction으로 도출됨
- 그렇기에 과도한 일반화가 되고 확고한 선호를 가진 사용자에게 전혀 연관없는 추천을 하게 될 것(섬세한 추천 불가)
3. recommender system overview

앱 추천시스템은 위 그림과 같이 구현된다.
1. user가 구매하거나 클릭을 하면 user의 Query가 생성된다.
2. datbase로부터 해당 Query에 적합한 후보 앱들을 retrieval한다.
3. 랭킹 알고리즘을 통해 후보 앱들의 점수를 매겨 정렬한다.
* 점수는 user 정보 x가 주어졌을 때, user가 앱 y에 action할 확률인 P(y | x)를 구한다.
wide and deep 모델은 랭킹 알고리즘으로써, 이런 후보 앱들의 점수를 매겨 리스트업해주는데 사용된다.
4. wide & deep learning
해당 논문에서 wide & deep learning을 사용한 랭킹 모델을 제안한다.

4.1 the wide component
좌측 모델과 같이, wide model은 y = w^T * x + b 형태의 일반적인 선형 모델이다.
해당 식에 x에 해당하는 feature set은 raw feature과 transformed feature을 포함한다.
(raw feature = 연속형 변수, transformed feature은 범주형 변수를 적용하기 위해 transformation 식을 활용해 식에 적용 가능하도록 변환한 변수로 생각하면 되겠다)
이때 transformation은 cross-product transformation으로 다음과 같이 나타낼 수 있다.
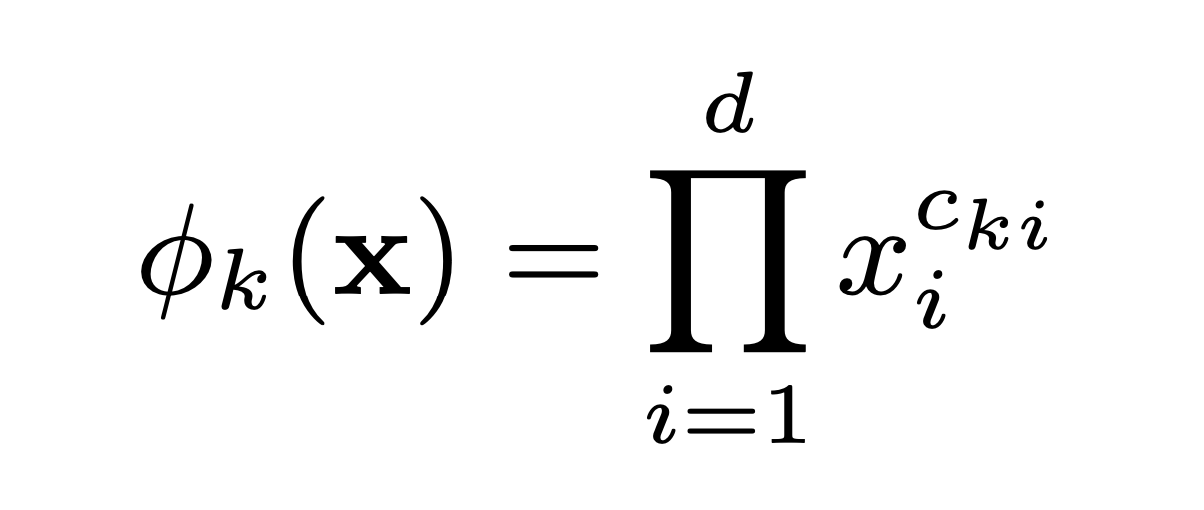
binary feature 가정에 따라 구성하는 feature가 모두 1인 경우에만 cross-product transformation 값은 1이 된다.
예를 들어, gender(남, 여 = 1, 0), education(높음, 낮음 = 1, 0), language(영어, 한국어= 1, 0) 3개의 변수가 있다고 하자.
유저 x는 남자고, 학업은 낮고, 한국어를 쓴다면 유저 x의 벡터는 다음과 같이 나타낼 수 있다.
x = [gender, education, language] = [남, 낮음, 한국어] = [1, 0, 0]
만약 2가지 경우의 feature transformation

이때, C는 번째 feature를 transformation에 사용되는지 여부를 나타낸다.
예를 들어,. 예를 들어 는 gender와 language를 사용하는 변환이므로, C_21, C_23은 1이 되어 식에 적용된다.
결과적으로 user A의 경우 male이면서, eng를 사용하지 않으므로 ϕ_2 transformation 값은 0이 된다.
cross-product transformation은 이진 변수 간의 interaction을 찾는 역할이며, 이는 generalized linear model에 선형성을 더해주는 역할을 한다.
4.2 the deep component
위 그림에서 오른쪽 모델과 같이, 순방향 신경망(feed-forward neural network)이다. categorical feature들로 인해 초기 입력값은 'language = 영어'와 같이 feature string이다. 각각의 희소하고 고차원의 범주형 변수를 저차원의 dense vector로 변환해준다. 즉, 임베딩해준다. 임베딩 벡터는 초기 랜덤값으로 주어지며 손실함수가 최소화되도록 모델 훈련한다. 히든 레이어는 다음 계산식으로 실행된다.

4.3 joint training of wild & deep model
wide 모델과 deep 모델을 joint training하기 위해, 각각의 Output Log Odds의 가중치 합을 사용하여 결합한다. 그리고 이렇게 나온 예측값은 하나의 로지스틱 손실함수에 들어갈 값으로 사용된다.
*Log Odds : odd에 log를 취한 것. 이때, log의 밑은 e.
특정 데이터가 positive class에 속할 확률을 표현하는 방식 중 하나.
odd = 특정사건이 발생할 확률 / 특정사건이 발생하지 않을 확률.
odd는 0과 양의 무한대 값을 범위로 갖는데, 이는 log함수의 도메인과 일치.
이때 Ensemble이 아닌 joint training을 사용한 이유는 다음과 같은 두 가지라고 한다.
1. joint training은 가중치 합 계산 뿐만 아니라, wide & deep의 모든 파라미터들을 동시에 최적화한다.
2. wide 모델은 소수의 cross-product feature transformation으로 deep 모델의 약점만 보완하면 된다.
wide & deep model joint training은 mini-batch stochastic optimization을 사용하여 output의 gradient를 wide와 deep 모델에 동시에 역전파하여 학습한다. 논문에 따르면, wide 모델에서는 optimizer로 FTRL(Follow-the-regularized-leader) 알고리즘을, deep 모델에서는 Adagrad를 사용했다고 한다.
다음은 wide & deep 모델의 prediction이다. 여기서 좌항은 특정 앱을 acquisition할 확률로 보면 되겠다. 각 모델에서 나온 결과를 더해 sigmoid 함수 σ( )를 통과시킨 결과가 최종 output이 된다.

5. System Implementation

5.1 Data Generation
훈련 데이터는 특정 시간 동안 사용자와 앱 노출 데이터를 통해 생성한다. 이때 레이블은 app acquisition인데, 1이면 노출된 앱이 설치됨을 의미한다. 범주형 변수 문자열을 정수 ID로 매핑하는 테이블인 Vocabularies도 Data Generation 단계에서 생성된다.
5.2 Model Training

본 논문의 구현 파트에서 사용된 모델 구조는 위 그림과 같다. 훈련 중에 입력 레이어는 훈련 데이터와 vocabularies를 가져와 레이블과 함께 희소하고 dense한 피쳐들을 생성한다.
(그림 우측에 표현) wide component는 설치된 앱의 사용자와 노출 앱들의 cross-product transformation으로 구성되어 있다.
(그림 좌측 하단에 표현) deep component의 경우, 32차원의 임베딩 벡터가 각각의 범주형 피처들에 대해 학습한다. 그리고 모든 임베딩 벡터들을 연결지어 대략 1200차원의 dense 벡터로 변환한다. 그 후 3개의 ReLU 레이어를 거친다.
이후, 양쪽에서 최종적으로 도출된 값들을 활용해 앞서 다룬 wide & deep 모델의 prediction에 대입하여 값을 도출한다.
wide & deep 모델은 5000억개 이상의 사례들로 훈련된다. 이때 기존 모델의 경우 새로운 학습 데이터셋이 생성될 때마다 모델을 다시 학습한다면 비용과 지연시간 문제가 발생하게 된다. 따라서 본 논문에서는 이전 모델의 임베딩과 선형 모델 가중치로 새로운 모델을 초기화하는 warm-strarting 시스템을 구현했다.
5.3 Model Serving
모델이 훈련되고 검증되면 model serving을 한다. 각 요청에 대해 서버는 앱 검색 및 사용자 피쳐로부터 앱 후보셋을 받아서 각 앱에 점수를 책정한다. 그러면 최고점부터 최저까지 앱 랭킹이 매겨지고 이를 사용자에게 노출시킨다.
6. Conclusion
wide and deep 모델은 memorization에 특화된 wide 모델과 generalization에 특화된 deep 모델을 결합한 것이다. 논문에 따르면 FM(factorization machine)의 아이디어로 시작되었다고 한다. FM은 linear 모델로 generalization을 위해서 저차원의 두 임베딩 벡터를 내적과 같은 계산을 통해 fatorizing한다.
wide & deep은, wide model 파트는 linear 모델을 사용하므로 cross-product feature transformation을 사용해 sparse feature interaction을 효과적으로 memorize한다. 또한 deep model 파트는 deep neural network을 활용하기에 저차원 임베딩을 통해 보이지 않는 feature interaction을 generalize할 수 있다. 따라서, FM의 이점과 한계를 모두 가졌다고 볼 수 있다.
'rainbow > 논문' 카테고리의 다른 글
| [논문] A new topic modeling based approach for aspect extraction in aspect based sentiment anlysis: SS-LDA (0) | 2023.08.16 |
|---|---|
| [논문] Collaborative Filtering for Implicit Feedback Datasets (0) | 2023.08.16 |
| [논문] 초록(abstract) 작성법 (0) | 2022.07.25 |


