
think deeply
[자연어 처리] 구문 분석 (part.1 구구조 구문 분석) 본문
구문분석이란
- 구문 분석: 자연어 문장에서 구성 요소들의 문법적 구조를 분석하는 기술
· 문법적 구조 정보를 자동으로 추출함으로써 자연어처리 기술(기계 번역, 정보 검색 등)에서 문장의미의 분석을 돕는 세부 기술로 활용 가능
- 구문 문법 : 언어학에서 문법적 구성요소들로부터 문장을 생성하고, 또 반대로 문장을 구성요소들로 분석할 때 활용하는 문법
→ 구문 분석에서 구문 문법을 정의하는 것은 중요한 요소 중 하나이다. 구문 분석의 목표가 자연어 문장의 문법적 구조를 '구문 문법'에 따라 자동으로 분석하는 것이기 때문에 이를 위해선 구문 분석을 통해 추출하고자 하는 문법 구조 정보를 정의하는 과정(구문 문법 정의 과정)은 중요한 절차이다.
- 구문 문법은 크게 구구조 문법, 의존 문법으로 나뉜다
구문 중의성이란
자연어 문장의 구문 구조가 다양한 방식으로 분석될 수 있는 특징을 구문 중의성이라고 한다.
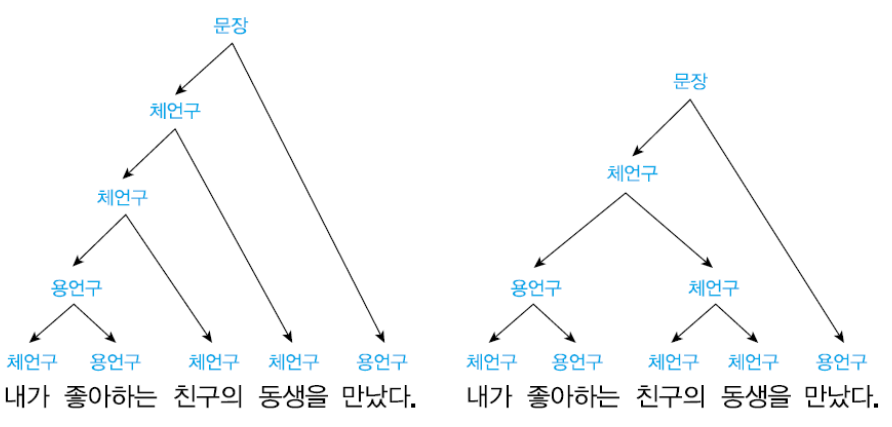
- 하나의 문장에서 가능한 구문 구조가 여러 개일 경우 구문 중의성이 발생
(위 예시의 경우, 한 문장이 두 개의 구문 구조 가능)
- 이를 해결하기 위해서는 의미, 문맥 등의 추가적인 정보가 필요
→ 구문 분석 결과가 잘못되었을 경우 이후 단계들에서 오류를 전파할 가능성이 있어 구문 분석 기술에는 구문 중의성 해소를 위한 방법이 요구된다
구구조 구문 분석
- 구구조 구문 분석 : 구구조 문법에 기반한 구문 분석 기술
· 구구조 문법은 단어들과 단어들로 구성된 절의 계층적 관계에 따라 구성된 문장 구조를 분석
· 문장 구성 요소의 구조가 비교적 고정적인 언어(ex. 영어)에 적합하다
cf. 한국어는 가변적인 형태가 많은 언어라 부적합
▶ 규칙기반 구구조 구문 분석
- 인간이 가지고 있는 언어학적 지식을 컴퓨터가 이해할 수 있는 형태의 문법 규칙으로 미리 정의하여 이를 자연어 문장에 정의함으로써 구문 분석을 수행하는 형태
- 문법 규칙의 형태로 '구구조 문법'을 활용
· 구구조 문법 : 자연어 문장을 하위 '구성소'들로 나눔으로써 문장 구조를 나타내는 문법
· 구성소 : 한 개의 단위처럼 기능하는 일련의 단어들을 의미
· 구구조 문법의 구조 : A→BC (구성소 A가 하위 구성소 B와 C로 분석될 수 있음을 의미)
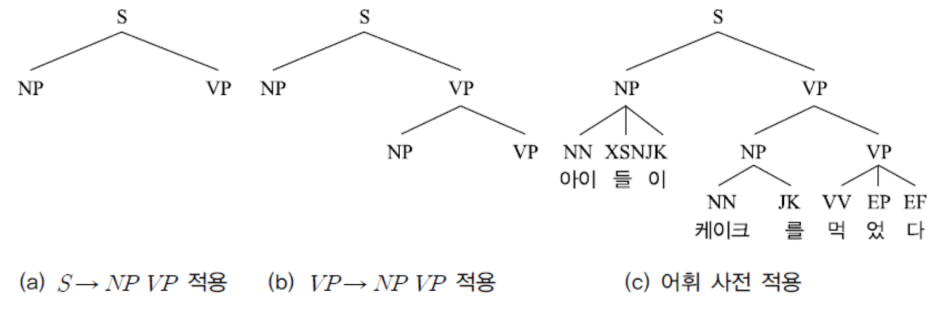
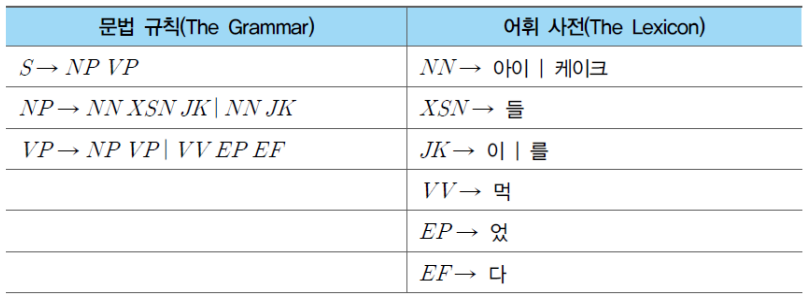
※ 문법 규칙: 문장의 구성소가 하위 구성소로 분석되는 규칙
※ 어휘 사전: 문법적 구성 요소에 해당하는 자연어 단어 정의
위 문법 규칙이나 어휘사전에서 S는 문장 전체를 의미하며, 나머지 영문 대문자는 구성소를 의미한다.
더불어, 'ㅣ'는 '또는'을 나타낸다.
▶통계 기반 구구조 구문 분석
- 통계적 구구조 문법을 활용하여 이를 바탕으로 구문 분석을 수행하는 접근 방법이다
- 문법 규칙은 확률적 구구조 문법으로 표현이 되는데, 이 문법에서는 각 규칙에 대한 조건부 확률이 정의된다
-확률적 구구조 문법 생성 규칙: A→ BC[p] (※ p : 구성소A가 하위 구성소 B와 C로 분석될 조건부 확률)
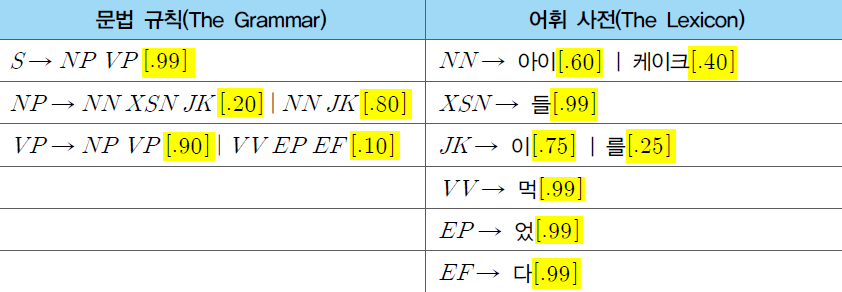
- 확률적 구구조 문법 규칙의 두 가지 계산법이 있다.
1. 사람이 직접 태깅한 '구구조 구문 분석 코퍼스'로부터 각 규칙이 나타나는 조건부 확률 계산
2. 태깅되지 않은 자연어 문장들을 구구조 구문 분석을 수행함으로써 문법 규칙들의 조건부 확률 조정
→ 각 문법 규칙의 조건부 확률에 기반해서 구문 분석 결과 전체의 확률 계산 가능
→ 적용된 문법 규칙들의 조건부 확률을 모두 곱함으로써 구문 분석 트리의 전체 확률 계산
※계산식은 생략하도록 한다. 아래 그림 정도로 이해해두면 될 것
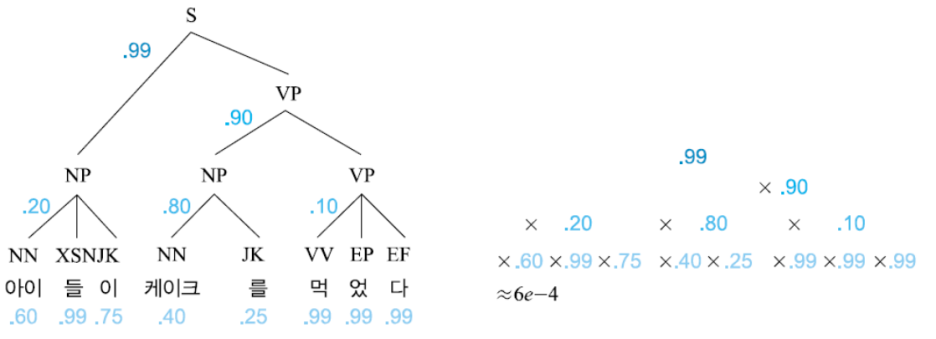
→ 각각의 구문 분석 트리는 위와 같이 확률 계산이 가능하다
→ 이와 같은 방식으로 주어진 자연어 문장에 대해 가능한 여러 형태의 구문 트리들을 각각 계산하여 가장 높은 확률을 지니는 것을 분석 결과로 도출
▶딥러닝 기반 구구조 구문 분석
- 인간이 구축한 구구조 구문 분석 데이터셋으로부터 딥러닝 모델을 학습하여 구문 분석하는 접근 방법
· 자연어 문장의 구조적 정보와 의미적 정보를 입력으로 하여 구성소들의 구조를 예측
★전이 기반 파싱: 딥러닝 기반 구구조 구문 분석의 대표적 방법
- 자연어 문장을 한 단어씩 읽으며 현재 단계에서 수행할 액션을 선택하는 방식으로 문장 전체 구구조 구문 분석
- 전이 기반 파싱의 대표적인 방법인 이동-감축 파싱(Shift- Reduce Parsing)을 아래에 설명하겠다
- 각 전이 단계에서 선택할 수 있는 액션: 이동(shift), 단항 감축(unary-reduce), 이항 감축(binary-reduce)
· 이동 연산 : 자연어 문장에 포함된 단어를 순차적으로 스택에 이동시키는 연산
· 감축 연산 : 스택에 저장된 하나 또는 두 개의 구성소를 꺼내 상위 구성소로 감축한 뒤 이 상위 구성소를 다시 스택에 이동시키는 연산
- 오라클(Oracle) : 각 전이 단계에서 어떤 액션을 선택할 지 결정
· 딥러닝 전이 기반 파싱에서는 RNN 인코더로 계산한 자연어 문장 및 각 단어의 특징 벡터, 스택의 현재 상태 등을 입력으로 받는 이 오라클이 딥러닝 모델이다
※ RNN : 순환 신경망
※ 인코더 : 주로 입력 신호를 컴퓨터 내부에서 사용하는 코드로 변경하는 것
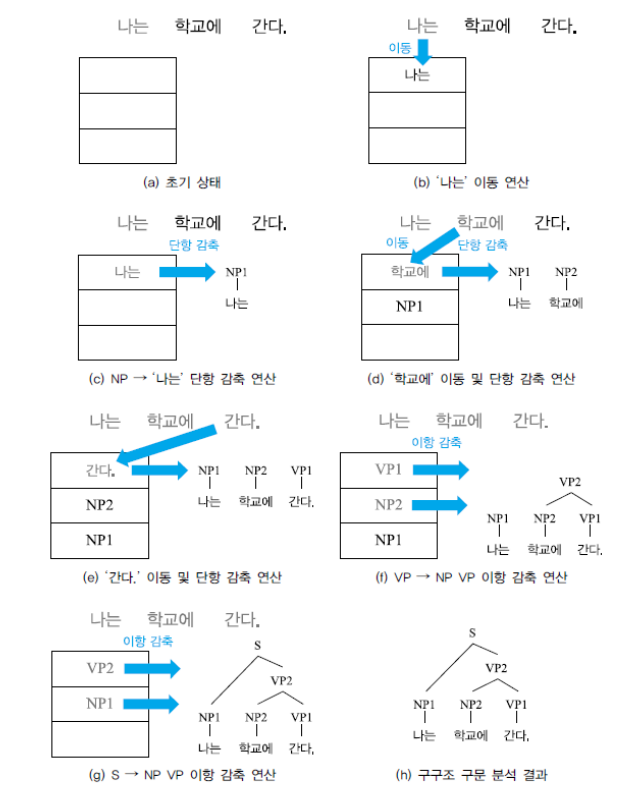
a. '초기 상태'로 스택이 비어있다
b. 스택이 비어 있기에 감축 연산 수행이 불가하다→문장 첫 단어 '나는'을 스택으로 이동(이동 연산)
c. 오라클이 스택의 최상단 '나는'에 단항 감축 연산을 수행하거나 다음 단어인 '학교에'를 스택으로 이동시킬지 선택을 하게 된다→오라클의 자체적 선택으로 단어 '나는'을 NP1(명사구)로 감축(단항 감축 연산)
d. 단어 '학교에'를 스택에 이동시키고(이동), NP2(명사구)로 감축(단항 감축 연산)
e. 오라클이 단어 '간다'를 스택으로 이동시키거나 NP1과 NP2의 이항 감축 연산 중 선택을 하게 된다→ 여기서 '나는'과 '학교에'가 결합하여 하나의 절을 구성할 수 없어 오라클 판단으로 '간다'를 스택으로 이동(이동) → 그 후 VP1(동사구)으로 감축(단항 감축 연산)
f. 스택의 최상단 두 개를 선택했을 때 '학교에'와 '간다'를 결합하여 '학교에 간다'라는 구를 구성할 수 있기에 이항 감축 연산
g. '나는'과 '학교에 간다'를 결합하여 '나는 학교에 간다'라는 구가 구성 가능하기에 또 다시 이항 감축 연산
h. 이리 하여 이동-감축 파싱에 따른 구구조 구문 분석을 완료→ 구문 분석 트리 구축
◆ 전이 기반 파싱의 장단점
장점: 입력된 자연어 문장에 포함된 단어 수에 선형적인 전이 액션으로 구문 분석이 가능하다
*참고* 데이터 분석에서 나오는 '선형적'은 Linear보다 Sequence를 의미할 때가 더 많다
단점: 각 전이 액션을 선택할 때 문장 전체의 문법적 구조를 고려하기 힘들다. 따라서 문장 내 거리가 먼 단어들 간의 의존 관계를 분석하는 것이 어렵다.
예를 들어, '내가 좋아하는 친구의 동생을 만났다'에서 내가 좋앟는 주체가 친구의 '동생'일 때, 나와 동생 사이의 거리가 멀어 이 둘 간의 의존관계 분석은 어려움. 따라서 오류 전파에 취약하다.
▶의존 구문 분석은 이어서 다음 글에
'rainbow > 자연어처리' 카테고리의 다른 글
| [자연어처리] 워드 임베딩 (0) | 2022.07.26 |
|---|---|
| [자연어처리] 개체명 인식(Named Entity Recognition:NER) (0) | 2022.07.21 |
| [자연어처리] 형태소분석 (0) | 2022.07.21 |
| [자연어처리] N-gram (0) | 2022.07.21 |
| [자연어처리] 텍스트의 전처리 (0) | 2022.07.21 |



