[자연어처리] 자연어 기초 개념
자연어 처리란?
▶ 자연어: 사람들의 사회생활에서 자연스럽게 발생하여 쓰이는 언어
- 흔히 대비되는 개념으로 인공언어가 있다. 컴퓨터에서 명령을 하기 위해 제약을 더하여 프로그래밍 언어와 같은 것을 의미한다.
▶자연어처리: 사람들이 사용하는 자연어를 컴퓨터를 이용하여 이해하고 생성하도록 하는 제반의 연구
- 자연어처리의 과정은 크게 NLU, NLG로 나뉜다.
· NLU(자연어 이해): 컴퓨터로 들어온 언어의 의미를 파악하여 의미 표현 형태로 변화시키는 과정
→ 단어, 구,문장과 같이 언어구조에 대한 이해를 다루는 데 더 초점을 맞추며, 구문 뿐만 아니라 의미에도 중점 을 둠. 인간의 이해를 위해 기계의 해석이 들어간 것이라 보면 쉬움.
· NLG(자연어 생성): 주어진 의미를 표현하기 위하여 컴퓨터에서 해당 의미를 나타내는 언어를 생성하는 과정
→시스템 계산의 결과를 사람이 사용하는 자연스러운 문장으로 만들어주기 위해 필요. 우리가 실생활에서 접할 수있는 amazon Alexa나 google AI-assistant를 떠올려보면 된다.
-자연어 처리는 우리가 자주 접하는 인공지능 스피커와 같이 음성인식, 개인비서 서비스 등에 많이 활용된다.
자연어 처리가 까다로운 이유
자연어 처리가 어려운 이유는 크게 세 가지로 나누어 볼 수 있다.
아래와 같은 이유로 처리 복잡도가 상승하게 된다.
▶언어의 중의성
-한국어 '배'에 담긴 의미는 「바다에 뜨는 배」, 「사람의 배」, 「크기 비교의 단위」와 같이 다양하게 쓰인다
-영어'read'는 「읽다」, 「read의 과거 분사」로 2개 이상의 의미를 지닌다
- 비꼬는 의미의 "참 잘 했다" 또한 상황에 따라 다른 의미를 내포한다
▶규칙의 예외
- 언어의 규칙을 연구하는 분야인 형태론이라는 학문 분야가 있을 정도로 규칙이 어렵고 복잡
- 언어의 규칙에 예외가 존재한다. 영어 동사의 과거형에는 -ed가 붙지만 아닌 경우가 존재
- 숙어로 쓰인 동사나 명사인 경우는 원 단어의 규칙을 그대로 적용하기 어려움
▶언어의 유연성과 확장성
-단어와 소리의 개수는 유한하지만, 이를 조합하여 만들 수 있는 문장의 수/길이는 무한하다
-구조 문법을 사용한 확장성의 이해
-문장의 여러단어가 이루는 구조를 통해 문장이 구성된다는 문법 모델로 언어의 중의성을 해소 가능
자연어처리 연구의 패러다임
자연어처리 연구는 규칙기반, 통계기반을 거쳐 현재 대부분 딥러닝 기반으로 이루어 진다.
연구 패러다임이 이와같이 변화한 이유를 간략히 서술해보겠다.
1)규칙기반 : 언어의 문법적 규칙을 사전에 정의해두고 이에 기반하여 자연어를 처리
· 규칙기반의 자연어 처리 예시는 크게 기계번역, 명령인식이 있다.
-기계번역: 문장을 형태소 단위로 분해하고, 여기에 감지되는 규칙을 사용하여 번역
-명령인식: 문장에서 목적어, 동사 등이 위치하는 규칙을 이용하여 대상과 행동을 이해
(*기계번역은 이전에 사람이 정의해둔 규칙대로만 번역을 한다면, 명령인식은 '시리야, 오늘 날씨 알려줘' 하면 동사와 목적어를 찾는데 집중하여 '날씨'라는 대상과 '알려줘'라는 행동을 인지한다.)
·규칙기반의 문제점
- 규칙을 모두 수작업으로 입력해주어야 하기에 시간적, 비용적 부담이 크다. (기계가 규칙을 다 찾는 게 아니기에 다 입력해주어야함.)
- 한국어처럼 어순이 정형화되어있지 않으면 분석에 한계가 존재( 물주세요= 주세요 물: 어순이 정형화되지 않아도 의미 동일)
「규칙을 정할 때 더 정량적으로 하기위해 통계 기반으로 넘어간다」
2)통계기반: 언어에 어떤 규칙이 있다면 그 단어나 어구 사이에 통계적으로 유의미한 값이 도출된다는 가정
· 통계적인 분석을 위해서는 사전에 수집된 대량의 문장(코퍼스)을 처리해야한다.
· 조건부 확률이라는 수학적 개념이 가장 핵심
·통계기반의 문제점
- 선형적인 분석이기 때문에 복잡한 규칙을 처리하기엔 어려움이 존재
-여전히 수작업이 많이 필요한 통계 분석 자료 활용
3)딥러닝 기반: 신경망 구조에서 은닉층 수를 매우 많이 늘린 것
-기계학습을 활용하여 입력으로 들어올 데이터를 대입시켜 알고리즘이 스스로 연산의 가중치를 학습하게 한다
-신경망은 기계학습의 일종으로, 여러 입력을 가중치를 적용하여 합하고 활성함수에 통과시킨 후 값을 다음 layer로 전달, 입출력 층을 뺀 층을 은닉층이라 부름
→ 딥러닝 기반 자연어 처리는
1. 모델을 잘 구성하는 것이 중요(딥러닝을 활용한 분석이 모두 지니는 특징일테다)
2. 단순 통계적 분석보다 고차원적인 분석을 할 수 있어 자연어 처리 성능을 비약적으로 상승시킴
▶하지만 단점도 존재. 은닉층에서 여러 연산을 거쳐 정해진 가중치가 무엇을 의미하는 지 모델 개발자도 알 수 없음
4) 따라서 최근에는 XAI(설명가능한 AI)에 대한 연구가 활발히 진행중
(이에 대한 설명은 따로 피드를 추가하도록 하겠다. )
딥러닝을 사용하는 자연어 처리 순서
1. 어떠한 목적으로 자연어처리를 도입하는 것인지 결정
2. 목적과 관련한 학습데이터를 수집하고 구축
3. 학습데이터를 통해 학습시킬 모델 구조를 작성
4. 준비한 학습데이터를 이용하여 모델을 학습
5. 완성된 모델을 검증하고 실전에 투입
모델의 성능개선은 주로 2, 3단계에서 진행된다.
알아야할 개념
▶ 단어 임베딩 : 언어적 특성을 반영하여 수치화한 것을 의미
- 자연어로 되어있는 문장을 컴퓨터가 받아들일 수 있도록 하는 문장이 전처리 과정(모델의 일부)
-다양한 방법이 있으나, 단어간 연관성 등을 유지하는 벡터화하는 방법이 많이 쓰임
-문법적으로만 사용되는 단어(조사, be동사 등)는 일반적으로 삭제 (벡터의 길이만 늘어나고 분석량이 커지기만 할테니)
단어 임베딩 방법에 대해서도 향후 깊게 다루겠다. 여기서는 간략히만 다루고 넘어가도록 한다.
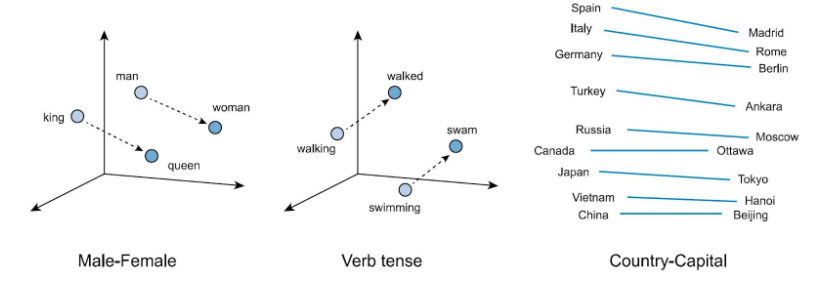
첫 번째 그림을 가지고 단어간 연관성 등을 유지하는 벡터화 방법을 간략히 설명해보도록 하자.
이 방법은 관계가 보존되는 것이다. 비슷한 조합들 사이에 벡터가 비슷한 지를 가지고 단어 간 연관성을 평가한다.
첫 번째 그림은 Male-Female에 대한 모델이다.
여기서 man과 woman은 어떠한 벡터 값으로 이어져있다.
그리고 man이 위치한 좌표에서 한 축의 값만 증가시킨다면 king이 존재한다.
그럼 king에 매칭되는 단어를 알아내기 위해서 어떻게 하면 될까?
man에 매칭된 woman에서 한 축의 값을 증가(man에서 king까지의 한 축 증가값만큼)시켜준다면 그에 맞는 단어 queen을 도출할 수 있다.
▶ 코퍼스 : "말뭉치" → 대량의 텍스트 데이터
- 매우 많은 수의 문장을 정제하여 모아둔 것
-통계/ 딥러닝 기반 자연어 처리에서 가장 핵심을 담당하는 자료
-연구 필요성에 따라 문장에 문장 성분을 기입하거나 대응하는 번역문을 쌍을 짓는 등, 연구에 사용할 정보를 같이 기입