[자연어처리] 텍스트의 전처리
자연어처리에서 텍스트의 전처리가 필요한 이유
-비정형 데이터(Unstructured Data)란 그림, 영상, 문서와 같이 형태와 구조가 다른 구조화되지 않은 데이터를 의미 (ex. 음성정보, 동영상정보, 시각정보)
-세상에 존재하는 대부분의 가공되지 않은 데이터는 비정형 데이터 형식이다. 따라서 비정형 데이터의 오류를 수정하는 과정(전처리 과정)은 필수적
텍스트 문서의 변환
- 우리가 분석을 목적으로 하는 파일로부터 텍스트를 추출하는 것이 전처리의 첫 단계
- 우리가 접하는 문서는 대부분 사람들이 읽기 쉬운 형태로 저장되어 있지만 파일 형식에 따라 저장 방법이 다르기에 시스템에서는 파일의 텍스트를 추출하는 것이

- 문서 파일을 문서로 바꾸는 작업을 수행 후에는 목표로 하는 언어의 어휘만 남아있어야 한다
- 따라서 여러 특수 문자나 불필요한 다른 언어 문자의 제거가 요구된다
- 방법은 다양하다
· 특수 문자 제거
· 문장과 관련 없는 특수 커멘드 또는 코딩을 규칙적으로 제거
· PDF의 경우처럼 텍스트를 문장 단위로만 끊게 함으로써 줄 바꿈과 같은 요소를 무시
· 문장 경계 인식
ex.

띄어쓰기 교정
- 한국어에서 띄어쓰기는 크게 의미분절, 가독성, 의미혼용 방지의 용도가 있다
· 의미분절 : 각 단어 및 조사간 구분을 명확하게 해줌 →더 간편한 프로세싱 가능
· 가독성 ; 문맥상 의미 파악에 대한 부담을 감소
· 의미혼용 방지 : 띄어쓰기의 부재시 의미혼용의 여지 증가 →문자열 처리 시 오류율 높아짐
ex. '아버지가 방에 들어가신다 vs 아버지 가방에 들어가신다'
※참고※
높은 정확도의 자연어 처리를 위해서 질 좋은 코퍼스(dataset)이 구성되어 있어야 하지만, 한국어의 특성 상 실생활에서 띄어쓰기가 제대로 되어 있지 않은 경우가 많아, 질 높은 코퍼스 구성도 중요한 task가 된다.
띄어쓰기 교정 방법
띄어쓰기 교정 방법은 규칙기반, 통계기반이 존재한다
▶ 규칙기반
- 형태소 분석기를 사용하는 규칙기반의 분석 방법
- 세우게 되는 규칙은 주로 어휘지식, 규칙, 오류 유형 등의 휴리스틱 규칙을 이용
(* 휴리스틱: 해결법이 정확히 해결되는가에 대한 문제를 배제하고, 경험과 직관을 통해 일반적을 좋은 해결법이나, 보다 간단한 해결법을 찾고자 하는 방법)
*장점
- 굉장히 높은 정확도
*단점
- 해당 규칙은 해당 답변에서만 사용 가능
- 무한한 경우의 수를 고려하여야 한다면 모든 규칙을 사람이 만들어야한다는 한계
- 어절 블록 양방향 알고리즘
· 조사나 어미로 쓰이는 음절이 지극히 제한적이라는 특성을 활용(조사는 체언 어절의 끝에 사용되므로 어절 경계일 가능성이 매우 높음) → 띄어쓰기가 되지 않은 입력 문장에서 어절 경계에 해당하는 부분을 인식하는 알고리즘
· 규칙기반 띄어쓰기 분석 방법에서 가장 많이 활용되는 알고리즘이다
▶통계·확률기반
- 말뭉치로부터 자동 추출된 음절 n-gram 정보를 기반으로 기계적인 계산 과정을 거쳐 띄어쓰기 오류 교정
- 언어 모델링 방법을 사용해 학습 말뭉치 내에서 수정 방향이 옳을 확률이 높은 후보들 중 가장 확률값이 높은 후보로 교정을 수행
<참고> n-gram에 대한 설명
*장점
-구현 용이
-어휘 지식 구축관리 및 미등록어에 대해 견고한 분석 가능
(이 장점은 사전과 비교하였을 때의 장점이다. 보통 사전에 없는 미등록어에 대한 분석은 어려운데, 통계기반 분석은 확률값을 기준으로 분석하기에 미등록어일지라도 확률값이 높다면 후보군에 속하게 되기에)
*단점
- 학습 말뭉치의 영향을 크게 받기에 정호가도 및 오류율이 높음
- 대량의 학습 데이터를 요구 - 한국어의 경우 띄어쓰기가 올바른 학습 말뭉치를 구하기 어려움
철자 및 맞춤법 교정
- 철자 교정 : 정확한 의미전송 및 정보교환에 필요
- 철자교정을 교정을 위해 맞춤법 검사를 진행
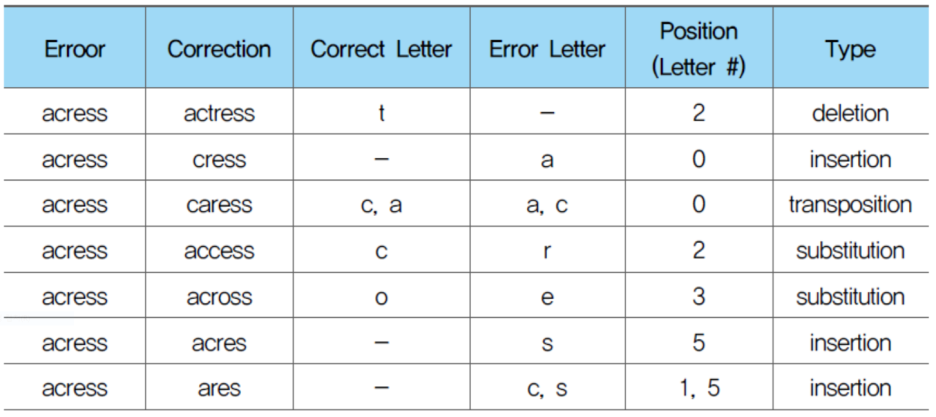
- 수정해야할 오류들은 크게 네 가지 경우
· 삽입(insertion): the를 ther처럼 추가적 문자를 입력하는 오류
· 생략(deletion): the를 th처럼 문자를 생략하는 오류
· 대체(substitution): the를 thw처럼 다른 문자를 대입하는 오류
· 순열(Transposition): the를 hte처럼 철자 순서가 뒤바뀌는 오류
철자 및 맞춤법 교정 방법
▶ 규칙기반
- 띄어쓰기 교정기의 규칙기반 방법과 장단점 흡사
- 언어 현상의 규칙성을 추가로 응용하는 방식(어절은 어절보다 작은 형태소들이 일정한 규칙에 따라 결합되어 이루어짐)
- 어절을 형태소들로 분절하는 '형태소 분석기'를 사용하는 방식이 존재
▶ 확률기반
- Bayesian inference model(베이지안 추론 모델)
· 올바른 교정 결과를 도출하기 위해 주어진 단어로부터 오타가 일어날 확률을 가지고 추론하는 방법
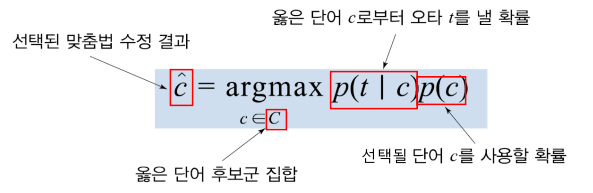
※argmax 수식: argmax f(x)가 주어진다면 f(x)가 최대값이 되는 x를 구하는 식

- 베이지안 추론 모델 수식에 확률값들을 대입하여 철자 교정 확률을 계산
- 오타가 일어날 확률이 가장 높은 후보군 "actress"를 선택해 감지한 오류를 대체